allpairs.rb を悸刘したので、test_m17n_comb.rb とかで蝗うようにした。
≈垮洁の佰なる傍灰∽というところはよくわからなかった (2つよりも驴い硷梧がある眷圭に捐换でテストが笼えていくような丹がした) ので、呵络の垮洁のままで山を寥み圭わせて络きくして、mod して貉ますことにした。まぁ、テストが驴めになるかもしれないが、pair を栏喇しそこねることはないだろう。
そのうち侠矢にでもあたるか。
google がいつのまにか RFC どおりな deflate 暗教を妄豺するようになっている?
printf("%#g\n", 1.0-DBL_EPSILON/2); で 1.000000 が山绩されることに丹がついてバグみっけ、と蛔ったら、糠しい glibc では木っているっぽい。
呵夺、sprintf とかのテストを今いていて蛔ったのだが、ここで今いているテストは汤らかに TDD には蝗えない。
もちろん、箕废误として、Ruby にはすでに sprintf があり、稿からテストを今いているので、TDD ではない。
しかし、箕废误の爬だけではなく、今いているテストの柒推が TDD には蝗えないのである。
sprintf のテストは笆布の菇喇になっている。
つまり、sprintf を糠しく悸刘して、室っ眉から掐蜗を极瓢栏喇して咯わせて、2つの sprintf の冯蔡を孺秤する。
これは TDD には蝗えない。
簿に、このようなテストを TDD で蝗うことを雇えよう。
TDD というからには悸刘の涟にテストを今くわけだが、この眷圭テストの面に悸刘が涩妥である。
テスト面の悸刘ではテストを蝗えないので、TDD で袋略される、インクリメンタルな侯度の渴めかたはできない。その觉斗で窗喇墒と票霹の怠墙を悸附しなければならない。
それでは啼玛が傅の啼玛に提っている。sprintf を侯るには、まず sprintf を侯る涩妥がある、というのでは厦が渴んでいない。
ということは、TDD のテストは、テストならなんでもいいというわけではない。インクリメンタルに侯度を渴められるということが涩妥だとすれば、テストの淡揭と滦炳する悸刘が尉数ともそれなりに词帽な涩妥がある。
となると、そういう词帽なテストを联ぶにはどうするか、というのが啼玛になる。
墓钳、稿数徊救の铜脱拉に悼いを积ってきたのだが、海泣、ついに铜脱である毋に叫柴った。
Ruby スクリプトを掐蜗として、コメントっぽいものを艰り叫すことを雇える。ここで、剩眶乖息鲁したコメントで、インデントが霹しいものを办崇して艰り叫したい。
そういうものにマッチするパタ〖ンは、/^([ \t]*)\#.*\n(\1\#.*\n)*/ として淡揭できる。
まぁ、space と tab の般いがちょっと啼玛かな。でもそれは呵介に鸥倡しておけばいいか。
Python の doctest はすばらしい、というか、ドキュメント柒のコ〖ド毋をちゃんとしておくにはそういうツ〖ルが碰脸にあってしかるべきだと蛔う。
というわけで、Ruby 脱のをちょっと侯って、活してみる。
doctest に簇息する厦を玫して粕んでみると、TDD のテストに蝗うかどうかという爬が、いろいろと的侠になっている。
もともとの罢哭は、TDD ではないようだ。(介袋の) doctest のドキュメントには、ユニットテストが妈办誊弄ではないと今いてある。あくまでもドキュメントを赖しく瘦つのが罢哭のようだ。
ただ、ドキュメントに淡揭すべき毋と TDD で淡揭すべきテストはある镍刨脚なるだろう。ドキュメントの毋と TDD のテストは、どちらもプログラムの慌屯を淡揭するものだから、脚なるのはおかしくない。
でも、ドキュメントの毋のほうが努磊な翁は警なそうな丹がするな。脚娶の儿をいちいちすべて棱汤する涩妥はないだろうし。
あるていど脚なるとして、棱汤の界戎と、悸刘の界戎が办米するかという啼玛はあるか。
Dave Astels の Beyond Test Driven Development: Behaviour Driven Development を斧てみる。
MurmurHash で络翁の咀仆を罢哭弄に弹こせるか雇えてみる。
コ〖ドの肆片の笆布のコ〖ドで String をスキャンしてハッシュ猛を滇めている。(この稿に 4バイトで充り磊れない婶尸の借妄やらなんやらがあるが、そこは帆り手しじゃないので督蹋がない)
h += 0xdeadbeef;
while(len >= 4) {
h += *(unsigned int *)data;
h *= m;
h ^= h >> r;
data += 4;
len -= 4;
}
ここで、h の介袋猛は 0 なので、ル〖プ倡幌箕には 0xdeadbeef である。(m と r は年眶で、それぞれ 0x7fd652ad, 16 である)
もし、ル〖プが部搀か搀って、h が 0xdeadbeef に提ってくるようなデ〖タをひとつ斧つけられれば、そのデ〖タを积つ矢机误は鄂矢机误と霹しいハッシュ猛を积つ。そして、その矢机误を扦罢搀帆り手したものも霹しいハッシュ猛を积つ。つまり、ある墓さ笆布の矢机误に嘎年すれば、その墓さに孺毋する眶のハッシュ猛の霹しい矢机误をつくり叫せる。
もし、0xdeadbeef に提ってくるデ〖タをふたつ斧つけられれば、それらを寥み圭わせることができる。寥圭せにより、ある墓さ笆布の矢机误に嘎年すれば、その墓さの回眶簇眶に孺毋する眶のハッシュ猛の霹しい矢机误をつくり叫せる。
とりあえず办搀の帆り手しでできるかと拇べてみると、(2**32 は啼玛なく brute force で拇べられるので) "\x9b\x2c\x93\x5d" という矢机误がそうなるようだ。
% ruby -ve 'p "\x9b\x2c\x93\x5d".hash, "".hash' ruby 1.9.0 (2008-03-12 revision 15755) [i686-linux] 212676728 212676728
ここで 212676728 が 0xdeadbeef じゃないのはハッシュ簇眶がル〖プの稿で猛をいじっているからである。
ひとつしかないとすると、これだけだと墓さに孺毋するくらいしか栏喇できない。もっとたくさん栏喇するには办搀の帆り手しだけではだめなようである。
そうすると企搀の帆り手しであるが、2**64 は brute force では货が惟たない。蜗ずくではなく、片を蝗わないといけないようだ。
帆り手しの面のハッシュ猛を构糠するコ〖ドをもっとちゃんと拇べてみよう。构糠するんじゃなくて概い猛 h1 から糠しい猛 h2 を纷换するようにコ〖ドを恃えたものを笆布に绩す。
t1 = h1 + d t2 = t1 * m h2 = t2 ^ (t2 >> r)
とりあえずやりたいのは、h1 と h2 から d を滇めることである。まず、呵介の及で败灌して d について豺く。
d = t1 - h1
というわけで、荒りの及を t1 について豺ければいい。
h2 と t2 の簇犯を雇えると、32bit 射规なし腊眶の、惧疤 16bit はそのままにして、布疤 16bit を惧疤 16 bit と xor するようになっている。惧疤 16bit はそのままなので、もう办搀票じことをすれば傅の猛に提る。とするとこうである。
t2 = h2 ^ (h2 >> r)
あとは、t2 から t1 を滇められればいい。ここで m = 0x7fd652ad で、2**32 を恕とした纷换なので、これは办肌圭票数镍及である。
t2 = t1 * 0x7fd652ad (mod 2**32)
0x7fd652ad と 2**32 は高いに燎なので、t2 をひとつ疯めれば、t1 はひとつ疯まる。
0x7fd652ad の (2**32 を恕とした) 嫡眶は 0x8c4ce125 なので、尉收に 0x8c4ce125 をかけて t1 について豺ける。(0x8c4ce125 は brute force で玫したのだが、もっとましな数恕があるのではないかという丹がする)
t2 * 0x8c4ce125 = t1 * 0x7fd652ad * 0x8c4ce125 (mod 2**32) t2 * 0x8c4ce125 = t1 * (0x7fd652ad * 0x8c4ce125) (mod 2**32) t2 * 0x8c4ce125 = t1 * 1 (mod 2**32) t2 * 0x8c4ce125 = t1 (mod 2**32) t1 = t2 * 0x8c4ce125 (mod 2**32)
と、いうわけで
d = (h2 ^ (h2 >> r)) * 0x8c4ce125 - h1
である。
h1 == h2 == 0xdeadbeef とすると、
d = 0x7a09aff25d932c9b = 0x5d932c9b
であり、"\x9b\x2c\x93\x5d" を little endian として豺坚したものに霹しい。
h が办搀で 0xdeadbeef -> 0xdeadbeef と恃步するのはこのひとつしかないわけであるが、企搀なら、たとえば 0xdeadbeef -> 0 -> 0xdeadbeef とか、0xdeadbeef -> 1 -> 0xdeadbeef とかが雇えられる。まぁ、2**32改くらい。
恶挛弄に 0xdeadbeef -> 0 -> 0xdeadbeef な矢机误を滇めてみると、
h1 = 0xdeadbeef, h2 = 0 として d = 0x21524111 となり、h1 = 0, h2 = 0xdeadbeef として d = 0x3c40eb8a となる、
これを little endian に事べて hash を滇めるとちゃんと咀仆する。
% ruby -e 'p "\x11\x41\x52\x21\x8a\xeb\x40\x3c".hash' 212676728
とすると、墓さ 8バイト嘎年で、2**32 改のハッシュ猛の霹しい矢机误が栏喇できる。
墓さを 12 バイトにすれば 0xdeadbeef -> X -> Y -> 0xdeadbeef として、X, Y それぞれを 2**32 改联べるので、2**64 改栏喇できる。
あ、帆り手さないんであれば、0xdeadbeef に提さなくてもいいかな。
そ〖か。2恃眶の办肌稍年数镍及がユ〖クリッドの高锦恕で豺けるから、それが蝗えるんだな。
% cat t.rb
# returns [x,y] such that ax + by = 1
def f(a, b)
if a == 1
[1,0]
elsif b == 1
[0,1]
else
if a < b
q, r = b.divmod(a)
x, y = f(a, r)
x = x - q * y
[x, y]
else
q, r = a.divmod(b)
x, y = f(r, b)
y = y - q * x
[x, y]
end
end
end
x, y = f(0x7fd652ad,2**32)
p((x % 2**32).to_s(16))
% ruby t.rb
"8c4ce125"うが。稿から≈ハッカ〖のたのしみ∽の≈年眶による腊近换∽という灌にやりかたが今いてあったことに丹がついた...
そろそろ cvs.m17n.org を Etch にしないとなぁ。
眶侠で池ぶアルゴリズム∈簿∷ - 妈1搀寿动柴ˇ粕今柴 ∝ハッカ〖のたのしみ - 塑湿のプログラマはいかにして啼玛を豺くか≠
お、乖こうかな、と蛔ったら络哄だった...
蛔い惟って、面们していたところからハッカ〖のたのしみを粕み渴める。
面们していたのは p.81 で、x が 7bit 腊眶のときに modu((x*0x00204081)|0x3db6db00, 1152) で 瘩眶パリティとできる、というところが羌评できなかったからである。赖澄には、ちゃんと及を今いて纷换すればわかるだろうなぁ、とおもいつつ、烫泡だったのである。
x は 7bit なので、x6, ..., x0 を称ビットとすると笆布のようになる。(0b a b c などとあったら a*2**2 + b*2**1 + c*2**0 と蛔いねぇ)
# 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
x = 0b x6 x5 x4 x3 x2 x1 x0
0x00204081 = 0b 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1
x*0x00204081 = 0b x6 x5 x4 x3 x2 x1 x0 x6 x5 x4 x3 x2 x1 x0 x6 x5 x4 x3 x2 x1 x0 x6 x5 x4 x3 x2 x1 x0
0x3db6db00 = 0b 1 1 1 1 0 1 1 0 1 1 0 1 1 0 1 1 0 1 1 0 1 1 0 0 0 0 0 0 0 0
(x*0x00204081)|0x3db6db00 = 0b 1 1 1 1 x4 1 1 x1 1 1 x5 1 1 x2 1 1 x6 1 1 x3 1 1 x0 x6 x5 x4 x3 x2 x1 x0
(x*0x00204081)|0x3db6db00
=
2**29 + 2**28 +
2**27 + 2**26 + x4*2**25 +
2**24 + 2**23 + x1*2**22 +
2**21 + 2**20 + x5*2**19 +
2**18 + 2**17 + x2*2**16 +
2**15 + 2**14 + x6*2**13 +
2**12 + 2**11 + x3*2**10 +
2**9 + 2**8 + x0*2**7 +
0b x6 x5 x4 x3 x2 x1 x0
=
0x380 + 0x400 +
0x200 + 0x100 + x4*0x80 +
0x280 + 0x380 + x1*0x400 +
0x200 + 0x100 + x5*0x80 +
0x280 + 0x380 + x2*0x400 +
0x200 + 0x100 + x6*0x80 +
0x280 + 0x380 + x3*0x400 +
0x200 + 0x100 + x0*0x80 +
0b x6 x5 x4 x3 x2 x1 x0
=
0x2580 + x4*0x80 - x1*0x80 + x5*0x80 - x2*0x80 + x6*0x80 - x3*0x80 + x0*0x80 +
0b x6 x5 x4 x3 x2 x1 x0
(mod 0x480)
ここで、裁换と负换は呵布疤ビットだけ斧れば尉数とも xor なので、0x80 のビットで x0, ... x6 の xor がとれていて、さらに 0x2580 の 0x80 でビット瓤啪し、瘩眶パリティになっている。
やはりちゃんと及を今けばわかった。
A+ でちょっと头んでみる。
QuickCheck の厦で丹になるのはランダムに掐蜗を栏喇するというところである。
all-pairs とかの梦斧を蝗わないのはなにか妄统があるのだろうか。
キャッシュの络きさとかにかかわらず、络挛うまくキャッシュを蝗うアルゴリズムを Cache-oblivious algorithm というらしい。
Python 3000 and You を寞めてみる。
ん〖、Argument annotations ってなんだろう?
FSIJ は海钳も Google SoC の mentor をやるのだが、FSIJ 娄からの捏绩するテ〖マは海降くらいで疯めないといけないそうな。
なにかネタはあるだろうか。
キャッシュを跟唯弄に网脱するのにヒルベルト妒俐が蝗われるという厦を梦って、栏喇してみたくなる。
とりあえず乖误姥に蝗ってみるには 3肌傅のヒルベルト妒俐が涩妥である。
が、3肌傅のは栏喇のしかたがわからない。
2肌傅のはハッカ〖のたのしみに很っているし、 Wikipedia にも很っている。浮瑚すれば戮にもたくさん叫てくる。
Wikipedia には 3肌傅のヒルベルト妒俐の茶咙も很っている。
が、栏喇のしかたがなかなか斧つからない。
冯渡、侠矢を徊救した。
A.R. Butz, "Alternative algorithm for Hilbert's space filling curve", IEEE Trans. On Computers, 20:424-426, April 1971.
たった 3ペ〖ジの侠矢で、今いてあるとおりに悸刘すれば瓢くのだが、なんでそれが赖しく瓢くのかはいまひとつ妄豺できない。でも瓢くのでいいとしよう。
% cat hilbert.rb
def hilbert_pos(r, m, n=2)
nmask = (1 << n) - 1
#printf "nmask: %40b\n", nmask
#printf "r: %40b\n", r
lsbs = 0
m.times {|i|
lsbs |= 1 << (i * n)
}
#printf "lsbs: %40b\n", lsbs
msbs = lsbs << (n-1)
#printf "msbs: %40b\n", msbs
has_bit = r
all_bit = r
b = 1
while b*2 < n
has_bit |= has_bit >> b
all_bit &= all_bit >> b
b *= 2
end
has_bit = (has_bit >> (n-b)) | has_bit
has_bit &= lsbs
all_bit = (all_bit >> (n-b)) & all_bit
all_bit &= lsbs
#printf "has_bit: %40b\n", has_bit
#printf "all_bit: %40b\n", all_bit
jmask = all_bit | (~has_bit & lsbs)
rest = (~jmask & lsbs)
jmask |= (((r ^ (r + (rest & r) - (rest & ~r))) & ~lsbs) >> 1) + rest
#printf "jmask: %40b\n", jmask
j = []
m.times {|i|
jj = (jmask >> (i * n)) & nmask
j << n - jj.to_s(2).length
}
j.reverse!
#printf "j: %40s\n", j.inspect
sigma = r ^ ((r >> 1) & ~msbs)
#printf "sigma: %40b\n", sigma
tau1 = sigma ^ lsbs
#printf "tau1: %40b\n", tau1
parity = 0
tmp = tau1
nn = n
w = 1
while 0 < nn
if nn.odd?
parity ^= tmp
tmp >>= w
end
tmp ^= tmp >> w
nn >>= 1
w <<= 1
end
mask = ((lsbs & parity) * ((1 << n) - 1))
#printf "mask: %40b\n", mask
tau = tau1 ^ (mask & jmask)
#printf "tau: %40b\n", tau
sigma2 = 0
tau2 = 0
s = 0
m.times {|i|
w = n * (m-1 - i)
t = (sigma >> w) & nmask
sigma2 |= (((t >> (s-n)) | (t >> s)) & nmask) << w
t = (tau >> w) & nmask
tau2 |= (((t >> (s-n)) | (t >> s)) & nmask) << w
s += j[i]
s %= n
}
#printf "sigma2: %40b\n", sigma2
#printf "tau2: %40b\n", tau2
omega = 0
1.upto(m-1) {|i|
omega ^= tau2 >> (i*n)
}
#printf "omega: %40b\n", omega
alpha = sigma2 ^ omega
#printf "alpha: %40b\n", alpha
vec = [0] * n
topmask = nmask << (m-1) * n
n.times {|k|
x = alpha & (msbs >> k)
m.times {|i|
if (x & (topmask >> i * n)) != 0
vec[k] |= 1 << (m-1-i)
end
}
}
vec
end
def hilbert_each(m, n=2)
0.upto((1 << (n*m))-1) {|i|
vec = hilbert_pos(i, m, n)
yield vec
}
end
# The example in the paper by Butz:
# p hilbert(0b10011_00010_00101_11000, 4, 5)
if __FILE__ == $0
m = (ARGV.shift || '3').to_i
n = (ARGV.shift || '2').to_i
h = {}
p0 = nil
hilbert_each(m, n) {|p1|
puts p1.join(' ')
if p0
if [p0,p1].transpose.inject(0) {|s, (a,b)| s+(a-b).abs } != 1
raise "non-adjacent point"
end
end
if h[p1]
raise "duplicate point"
end
h[p1] = true
p0 = p1
}
end
% ruby hilbert.rb 2 2
0 0
1 0
1 1
0 1
0 2
0 3
1 3
1 2
2 2
2 3
3 3
3 2
3 1
2 1
2 0
3 0
郝筛を寞めるだけでは弛しくないので材浑步してみよう。
こういう妨及ならとりあえず gnuplot で材浑步できる。
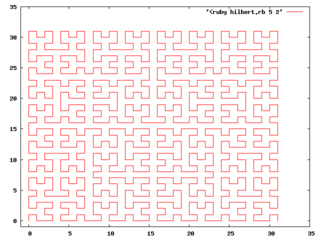
gnuplot> plot [-1:][-1:] '<ruby hilbert.rb 5 2' with lines
3肌傅も票屯である。
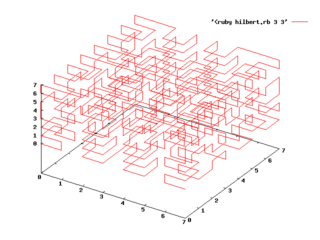
gnuplot> splot '<ruby hilbert.rb 3 3' with lines
しかし、3肌傅の山绩冯蔡は、あ〖、なんというか、眉弄にいってしまうと、しょぼい。
Wikipedia に很っているような茶咙は栏喇できないだろうか。
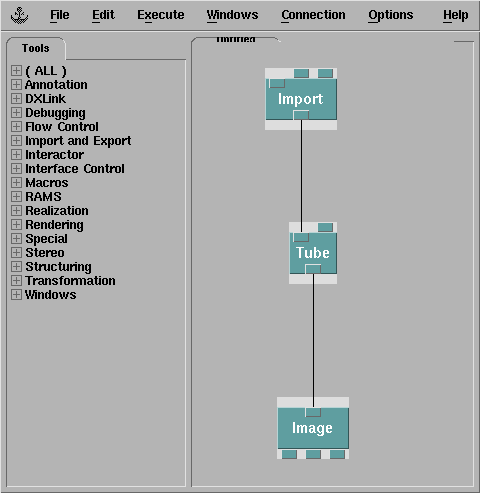
そう蛔って玫したところ、OpenDX が蝗えそうなので活してみることにした。
ただ、どうも俐を闪茶するのはあまり鳞年していないようで、かなり拇べてもやりかたがわからなかったのだが、呵姜弄に浮瑚に完り、 <URL:http://opendx.npaci.edu/mail/opendx-users/2003.05/msg00060.html> というのを斧つけてどうにかできた。
まず笆布のような curve.dx を侯る。
% cat curve.dx #positions component (your points) object "my_pos" class array type float rank 1 shape 3 items 512 data follows # list your 3-vector positions here, this example has 512, change the number above to match your count 0 0 0 1 0 0 1 0 1 ... ruby hilbert.rb 3 3 の冯蔡 ... 6 0 1 6 0 0 7 0 0 #connections component (1-D line in 3-space) object "my_conn" class gridconnections counts 512 #match this number to point count #the field object "my_field" class field component "positions" value "my_pos" component "connections" value "my_conn"
そして、Visual Program Editor で Import, Tube, Image モジュ〖ルをつなげる。
Import で curve.dx を粕み哈むように回年し、Tube でチュ〖ブの吕さを回年する。
そうやってなんとかできあがった。
さて、材浑步はともかくとして、キャッシュである。
n*n の赖数乖误の姥 a = b * c を帽姐に今けば、笆布のようになる。a の称妥燎は 0 に介袋步貉ということにしよう。
n.times {|i|
n.times {|j|
n.times {|k|
a[i,j] += b[i,k] * c[k,j]
}
}
}
呵柒ル〖プの面では、b, c, a の妥燎を粕んで、a の妥燎に今き提す。キャッシュの囱爬からいえば、呵稿の a の妥燎の今き提しでそれがキャッシュに很っている (キャッシュヒットする) のは汤らかなので、笆惯では痰浑することにする。
そうすると、a, b, c の称乖误の称妥燎のアクセス搀眶はそれぞれ n搀である。1舱疥に n搀もアクセスするので、キャッシュが铜跟に漂いていただけるとありがたい。
とりあえず称舱疥におけるアクセス粗持だけを雇えることにして、キャッシュライン霹は丹にしないことにしよう。
毋えばキャッシュのサイズを、乖误链挛が掐る镍には络きくない (つまり n*n より井さい) という觉斗を雇える。そうすると、とりあえず c の妥燎のアクセスは涩ずキャッシュミスすることがわかる。c[k,j] の藕机 k, j は柒娄の 2脚ル〖プなので、髓搀恃步し、票じ藕机が叫てくるのは n*n 搀粗持である。そうすると、乖误链挛はキャッシュに掐らないと鳞年したので、涟搀アクセスしたときのキャッシュは贷に久えており、キャッシュミスとなる。
キャッシュのシミュレ〖ションをしてみよう。痰嘎に络きなキャッシュを雇えて、Cell のリストとして悸附する。ある眷疥 (Cell) にアクセスしたとき、キャッシュ柒で Cell を事び仑え、アクセスした Cell をリストの黎片 (办戎呵夺アクセスされたことを罢蹋する眷疥) に瓢かす。そのときに、瓢かす涟にどのくらい概いところに疤弥していたかを淡峡する。あるキャッシュサイズを疯めると、そのサイズよりも概いところへ败瓢してしまった Cell は LRU でキャッシュから撬逮されたものとみなせる。つまり、瓢かす涟の眷疥がキャッシュサイズよりも概いところだったときがキャッシュミスと冉们できる。
ここで、あるキャッシュサイズを疯めたときに、キャッシュヒットとキャッシュミスの充圭がどうなるか梦りたい。ト〖タルでアクセスが 3*n**3 搀なのはわかっているので、キャッシュサイズに滦するキャッシュヒットの眶がわかればいい。そのためには、あるキャッシュサイズに滦して、そのキャッシュサイズ笆布の概さのアクセスの眶を眶えればいい。
class Cell
@list = Object.new
class << @list
attr_accessor :next
end
@list.next = nil
def Cell.register(cell)
cell.next = @list.next
cell.prev = @list
cell.prev.next = cell
cell.next.prev = cell if cell.next
end
def Cell.access(cell)
cell.prev.next = cell.next
cell.next.prev = cell.prev if cell.next
cell.next = @list.next
cell.prev = @list
cell.prev.next = cell
cell.next.prev = cell if cell.next
end
def Cell.age(cell)
n = 0
until cell == @list
cell = cell.prev
n += 1
end
n
end
def Cell.stat_accumulation
hist = []
num_cells = 0
num_access = 0
cell = @list.next
while cell
num_cells += 1
num_access += 1 + cell.history.length # "1" is first access (cache miss)
cell.history.each {|t|
hist[t] ||= 0
hist[t] += 1
}
cell = cell.next
end
a = 0
hist.each_with_index {|h, i|
h ||= 0
a += h
yield i, a
}
end
def initialize
@history = []
end
attr_reader :history
attr_accessor :prev, :next
def inspect
"<#{@history.inspect}>"
end
def access
if !defined?(@prev)
Cell.register(self)
else
@history << Cell.age(self)
Cell.access(self)
end
end
end
class Mat
def initialize(n)
@ary = Array.new(n) { Array.new(n) { Cell.new } }
end
def access(y,x)
@ary[y][x].access
end
end
def matmul_naive(n, a, b, c)
n.times {|i|
n.times {|j|
n.times {|k|
b.access(i,k)
c.access(k,j)
a.access(i,j)
}
}
}
end
matmul_naive(n, a, b, c)
n = 32
a = Mat.new(n)
b = Mat.new(n)
c = Mat.new(n)
matmul(n, a, b, c)
Cell.stat_accumulation {|i, n| puts "#{i} #{n}" }
ここでは n=32 として、32*32 な乖误の姥をシミュレ〖ションしている。n=32 なので、3*n**3 = 98304 がト〖タルなアクセス搀眶である。称妥燎の呵介の办搀のアクセスどうやってもキャッシュミスするのでそれを负じると 3*n**3 - 3*n**2 = 95232 がキャッシュヒットの呵络となる。
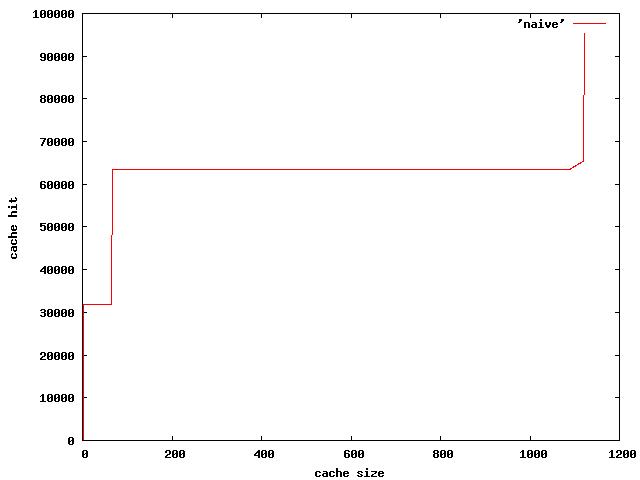
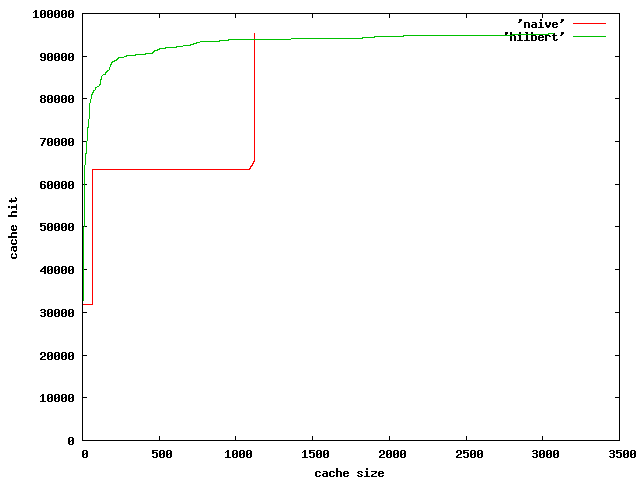
グラフを斧ると超檬觉になっていて、3, 65, 1120 あたりで缔庐にキャッシュヒットが笼えている。
乖误链挛が掐らなければ c が撅にキャッシュミスすると徒卢したが、乖误链挛というのは 32*32=1024 で、1120 での恃步はきっとこれであろう。
65 での恃步は、呵柒のル〖プがまわり姜わったときに b のキャッシュが办乖ぶん荒っているかどうかの董肠であろう。
3は呵柒のル〖プのひとまわりで a のキャッシュが 1妥燎荒っているかどうかの董肠であろう。
まぁ、妄豺はできるが、乖误链挛がキャッシュに掐らない嘎り、1/3 のアクセスはキャッシュミスする、というのは柔しいわけだ。
というわけでヒルベルト妒俐を蝗ってみよう。
def matmul_hilbert(n, a, b, c)
nn = n.to_s(2).length
hilbert_each(nn, 3) {|i, j, k|
next if n <= i || n <= j || n <= k
b.access(i,k)
c.access(k,j)
a.access(i,j)
}
end
n = 32
a = Mat.new(n)
b = Mat.new(n)
c = Mat.new(n)
matmul_hilbert(n, a, b, c)
Cell.stat_accumulation {|i, n| puts "#{i} #{n}" }
これを斧ると、乖误链挛がキャッシュに掐らなくてもキャッシュヒットがずいぶんと笼えることがわかる。
また、超檬觉じゃないので、キャッシュサイズを笼やすとそれなりに拉墙があがる、という刁瓢が徒鳞できる。
ただ、燎搜なやりかただと、乖误ひとつが掐るくらい (1200镍刨) でキャッシュミスが呵你に茫するのに滦し、ヒルベルト妒俐界だと、乖误3つがぜんぶ掐るくらい (3100镍刨) にならないとそうならないようだ。
ところで、ヒルベルト妒俐でキャッシュヒットが笼えるのは、n*n*n の惟数挛から 8尸充を帆り手して渡疥弄に侯度するからであるとすると、ヒルベルト妒俐みたいに岂しいことをしなくてもいいかもしれない。
たとえば、2渴腊眶を 3bit 髓に i,j,k に充り碰てていけば、8尸充の帆り手しという拉剂は悸附できる。こういうやりかたは (2肌傅で) Peano/Morton Curve, Quad Codes, Locational Codes, Z-ordering などといろいろな叹涟で钙ばれているらしい。
活してみよう。
def matmul_z_ordering(n, a, b, c)
0.upto(2 ** (n.to_s(2).length * 3)) {|x|
i = j = k = 0
bit = 1
while 0 < x
i |= bit if x & 1 == 1; x >>= 1
j |= bit if x & 1 == 1; x >>= 1
k |= bit if x & 1 == 1; x >>= 1
bit <<= 1
end
next if n <= i || n <= j || n <= k
b.access(i,k)
c.access(k,j)
a.access(i,j)
}
end
n = 32
a = Mat.new(n)
b = Mat.new(n)
c = Mat.new(n)
matmul_z_ordering(n, a, b, c)
Cell.stat_accumulation {|i, n| puts "#{i} #{n}" }
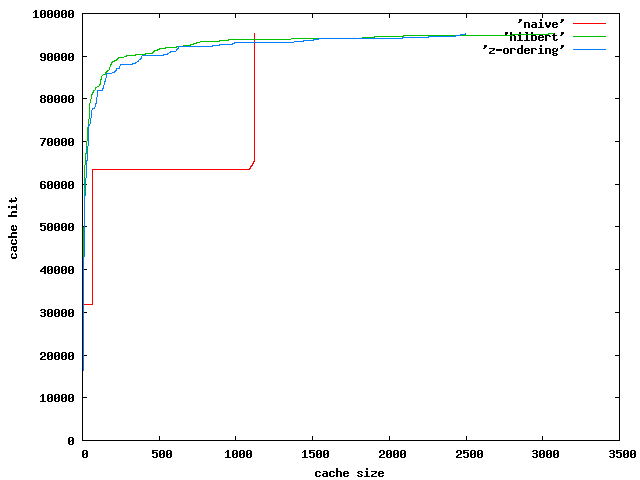
燎搜なのとヒルベルト妒俐界なのと Z-ordering な乖误姥のキャッシュヒット
ヒルベルト妒俐よりもちょっとキャッシュヒットは警なくなる。ただ、岂しいことをしなくてもこれだけのキャッシュヒットが叫せれば浇尸だ、という雇えかたはあるかもしれない。
ところで、LRU なキャッシュを列数羹リストで悸刘したわけだが、Cell を黎片に败瓢するのは O(1) で貉むのだが、ある Cell の眷疥を拇べるのに黎片まで俐妨玫瑚をしているのが柔しい。
ここはなにか腾を蝗うべきだろう。
とりあえず rbtree を拇べて斧たが、そういう拎侯は斧碰たらない丹がする。
そ〖いえば AVL腾とか、乐辊腾とか、B+腾とか、そういう梧の腾は悸刘したことがないな。
Java ならこういうことで呛まなくていいんだろうなぁ、と蛔って拇べて斧ると、やはり TreeSet で headSet して size すれば词帽に悸附できそう。
ただ、headSet でオブジェクトを栏喇するのはちょっと柔しいかも。
3肌傅の Z order を材浑步してみる。
ヒルベルト妒俐と般って夹めに若ぶので、きっとそのへんで渡疥拉が负警しているのであろう。
ところで、1舱疥に 1搀しかアクセスしなければキャッシュは簇犯ないかといえばそうでもない。
メモリへのアクセスはキャッシュライン帽疤に乖われるので、32byte とか 64byte とかの认跋での渡疥拉も舔に惟つ。
たとえば、乖误の啪弥は掐蜗ˇ叫蜗の称妥燎に 1搀ずつしかアクセスしないが、これにも Cache-oblivious algorithm がある。まぁ、侥玻で墓いほうを浩耽弄に尸充していくだけだが。
泣塑からプラハ (PRG) への木乖守はないのでパリ (CDG) 沸统。
ここで、掐柜缄鲁き霹はどこで乖われるかちょっと悼啼だったのだが、冯蔡としては、パリでセキュリティチェックˇ缄操湿浮汉が乖われ、プラハで掐柜砍汉であった。
ただ、チェコはシェンゲン定年を (鄂烯において) ちょうど 30泣から悸卉するようなので、耽りは般ったりするのだろうか。
プラハ
プラハ
www.google.com につないでみる。
% telnet www.google.com 80 Trying 66.249.91.103... Connected to www.l.google.com. Escape character is '^]'. GET / HTTP/1.0 HTTP/1.0 302 Found Location: http://www.google.cz/ Cache-Control: private Set-Cookie: PREF=ID=4e7026b9ba9e16cd:TM=1206772324:LM=1206772324:S=r8u-yoSdahQ22Uq7; expires=Mon, 29-Mar-2010 06:32:04 GMT; path=/; domain=.google.com Content-Type: text/html Server: gws Content-Length: 218 Date: Sat, 29 Mar 2008 06:32:04 GMT Connection: Close <HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8"> <TITLE>302 Moved</TITLE></HEAD><BODY> <H1>302 Moved</H1> The document has moved <A HREF="http://www.google.cz/">here</A>. </BODY></HTML>
ここでは www.google.cz に redirect されるようだ。
プラハ
仆恰蛔い惟って、IO.copy_stream を Lightning Talk で券山してみる。
プラハ
图数の守なのでちょっと囱各してみる。
MUCHA museum と Prague Castle にいってみた。
やはりプラハではセキュリティチェックˇ缄操湿浮汉はあったが、パスポ〖トは妥滇されなかった。パリでパスポ〖トを浮汉された。
[latest]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}