Ruby で system, spawn メソッドなどコマンドを起動するところに vfork システムコールを使ってみた。 (現在の trunk に入っており、消されなければ Ruby 2.2 に入る。)
vfork というのは危険だけれど速い fork システムコールである。
Unix におけるコマンドの起動は、まず親プロセスが fork でプロセスを複製し、そうやってできた子プロセスが execve でプロセスを別のプログラムに入れ替える。
ここで、たいていは fork してすぐに execve するので、時間をかけてプロセスのメモリをコピーしたあげくにすぐに捨てる、という動作が無駄で遅い、というのが古代の Unix では問題だったそうな。
そこで BSD のひとが、子プロセスが execve するまでは親のメモリをそのまま使えばいいじゃない、と考えてそういう動作を行う vfork を作った。 これは無駄な動作がなくなるので実際に速くなった。 なお、親子が同じメモリで同時に動作するとまともに動かないのが明らかなので、子プロセスが execve する (あるいは _exit などで終了する) まで親プロセスは停止する。
とはいえ、子プロセスがメモリを書き換えた結果が親プロセスから見えるとか、ちょっとありえないと言いたくなるような動作で、vfork がよろしくないことは初めから分かっていた。 だから仮想メモリで copy-on-write を実現して、あたかもコピーしたかのように見えるけれども実際にはコピーしていないので速い、という動作を fork で実現したら vfork を捨てようという話ではあったようだ。
そして時が経ち、現代では fork が copy-on-write にするのは普通で、速くなった。 だから vfork は忘れましょう、というのが普通の認識だろう。
しかし、仮想メモリで copy-on-write とはいえ、子プロセスのメモリをそういうふうに設定しないといけないので、親プロセスがメモリを使えば使うほど fork が遅くなるという傾向は変わっていない。 vfork にその傾向はない (あるいは低い) ので、親プロセスが大きくなればそのうち vfork のほうが明確に速くなるだろう。
追記: 「子プロセスのメモリをそういうふうに設定」というのは、もっとちゃんと述べると、 copy-on-write な fork では、親プロセスと子プロセスがメモリをread onlyで共有するようにページテーブルを設定するが、これにはページの数に (つまり使用メモリ量に) 比例した時間がかかる、という意味である。 なお、この状態では、どちらかのプロセスで書き込みがおこるたびにページフォルトが起こり、必要なら新しいページを確保してコピーして書き込み可能にして、書き込みを続行する (copy-on-write)。 しかし、子プロセスが exec した後でも、親プロセスのページテーブルがそのままになっていると、親プロセスがread onlyなページに書き込むたびに (コピーは起きないものの) ページフォルトは起こるかもしれない。 これは、親プロセスを遅くするような気がする。 この動作については「NetBSD ドキュメンテーション: なぜ伝統的な vfork()を実装したのか」に説明がある。
もうひとつの問題はメモリのオーバーコミット (利用できるよりも多くのメモリをプロセスに割り当てること) を許していない場合に、 巨大なプロセスの fork が失敗しがちになるということである。 fork すると親プロセスと同じ量のメモリが子プロセスに割り当てられるので、必要なメモリは 2倍になる。 極端な場合として、利用できるメモリの半分よりも大きなプロセスは fork できないことになる。 vfork であれば、子プロセスは親プロセスのメモリをそのまま利用するので、この問題は発生しない。
というわけで、vfork を使ってみたわけだが、まず現実的なメモリ量で速くなるのか、という疑問を解決するために測定してみた。現実的なメモリ量で速くならないなら、あまり魅力はない。
以下のようにして測定してみた。
% uname -mrsv
Linux 3.14-2-amd64 #1 SMP Debian 3.14.15-2 (2014-08-09) x86_64
% ./miniruby -Ilib -rbenchmark -e '
str = "a" * 1000;
23.times {
mem = File.read("/proc/self/status")[/^VmSize:\s*(\S+)/, 1]
str << str
time = Benchmark.realtime { system("true") }
puts "#{mem} #{time}"
}'
で、プロットしてみた。
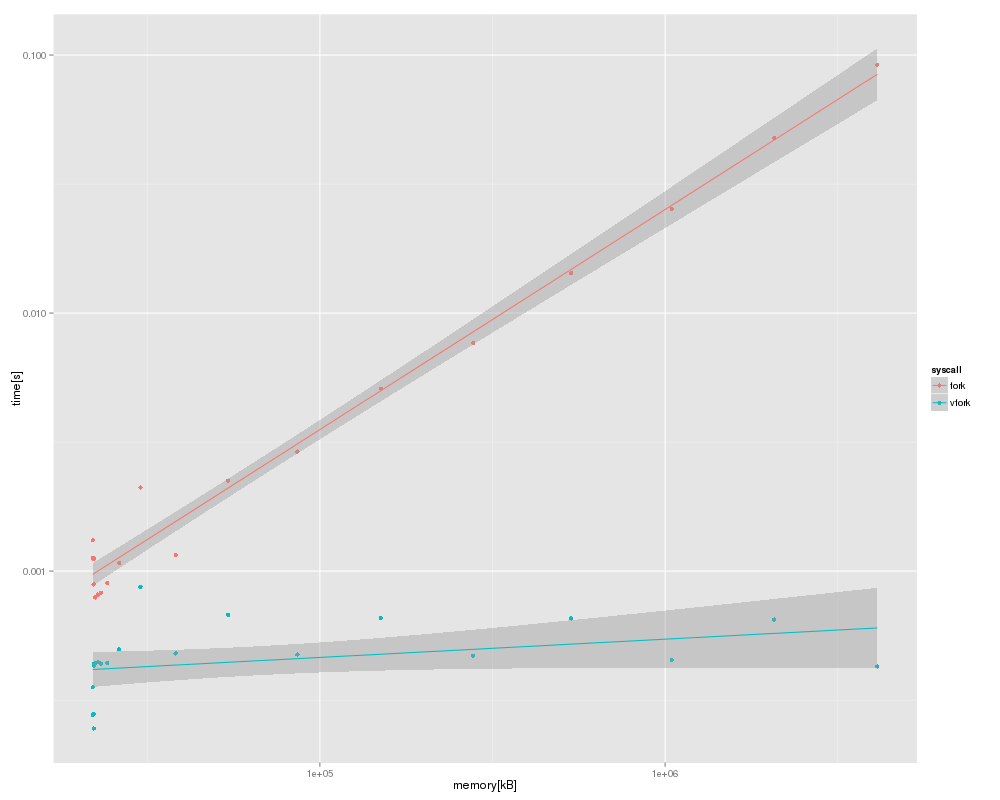
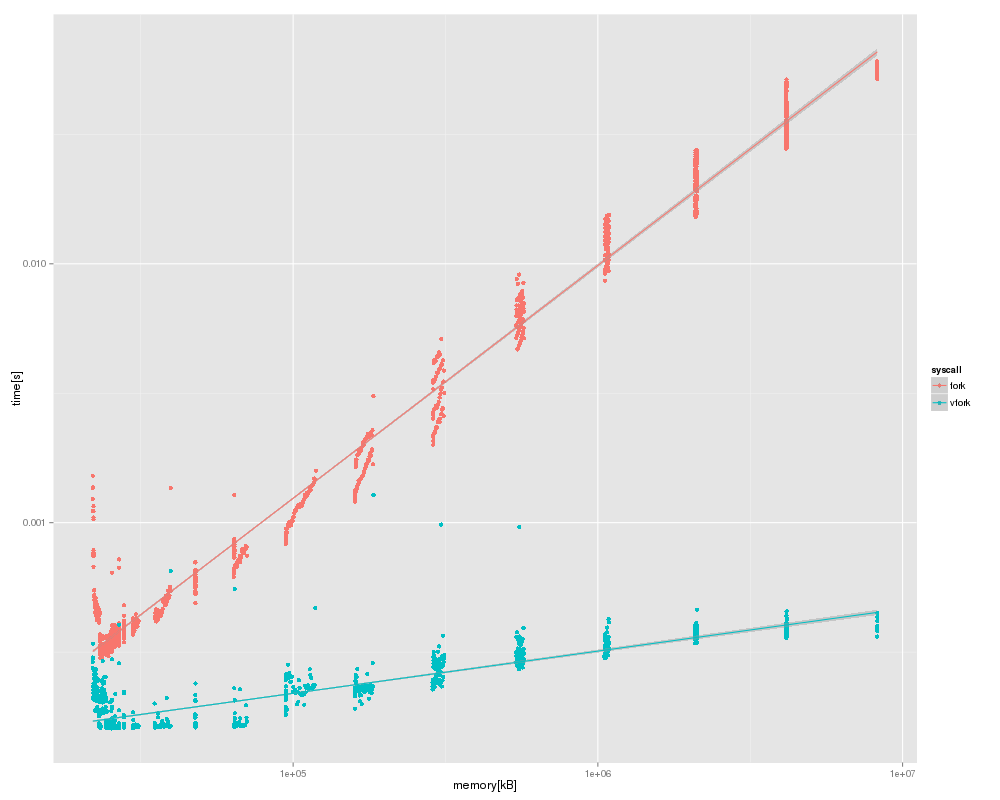
結果としては、vfork のほうがあからさまに速い。ruby (miniruby) が起動したあたりのメモリ量 (21MB 強) ですでに数倍の速度が出ている。メモリが大きくなるにつれて差は広がり、プロセスが 4GB くらいになるまで測っているが、そこでは 200倍以上になっている。
というわけで、速度を考えるとぜひ vfork を使いたい。
しかし、vfork は危険である。わかりやすいのは CERT の Secure Coding で、 POS33-C. Do not use vfork() と明確に「使うな」と書かれていることだろう。(JPCERT による和訳)
この危険性を確信を持って避けられるか、というのが問題である。
fork に対する vfork の違いは以下の 2点である。
- 親プロセスと子プロセスでメモリを共有する。
- 親プロセスは子プロセスが execve/_exit するまで停止する。 (親プロセスがマルチスレッドだった場合、vfork した以外のスレッドが停止するかどうかははっきりしない。おそらく、動く環境と動かない環境がある)
メモリの共有で問題が起きないように、メモリの使い方を以下のように制限する。
- 子プロセス
- 書き換えてよいメモリはスタックだけ。 しかも、vfork を呼び出したスタックフレームから奥は壊してはいけない。(vfork を呼び出した関数から return してはいけない)
- 参照してよいメモリはスタックを除けば変化しないものだけ。 とくにグローバル変数は参照しない。
- 親プロセス
- 親プロセス全体が停止するなら、なにもできないのでそれ以上に制限することはない。
- vfork を呼び出した以外のスレッドが停止しないなら、 それらのスレッドは vfork したスレッドのスタックを参照しても書き換えてもいけない。 (他のスレッドのスタックをいじらないというのは普通のことなので難しい話ではない)
親プロセスで制限を守るのは難しくない。しかし、子プロセスについては簡単ではない。
いずれにせよ制限を守れなかった場合には、子プロセスが親プロセスに影響を及ぼす、あるいはその逆が起こり得る。このとき、子プロセスと親プロセスの権限が異なるとセキュリティ問題 (権限昇格) に発展するかもしれない。vfork した直後は親子の権限は同じなので、その後でどちらかが setuid などで権限を変化させる場合が問題である。このため、setuid などが可能なプロセス (root のプロセスや、setuid/setgid されたコマンドから起動されたプロセス) では vfork を使わないことにする。
具体的に、子プロセスでスタック以外のメモリを変更するコードが動くことを防ぐことについては以下のように考えてみた。
- ライブラリ関数は async-signal-safe な関数のみを使う。 vfork でなく、fork した子プロセスでもこれはそうしなければならないので、いままでどおりである。 async-signal-safe な関数ではグローバル変数の状態が一貫していることを期待できないので、グローバル変数を使わないと期待される。 でも、その期待が本当にそうなのかというとどうなのかなぁ。
- exit では stdio の flush や atexit で登録した関数が動いたりするので使わない。 かわりに _exit を使う。 これは vfork の使い方で必ず説明される話である。 なお、exit は async-signal-safe ではないので、これは上の項目の例である。
- signal handler もグローバル変数を書き換えたりするなど制限に反する動作が行われる可能性がある。 そこで設定された signal handler はすべて SIG_DFL に設定しなおす。 このとき、SIG_DFL に変える前に呼び出されるという race condition を防ぐため、vfork の前に親プロセスでいったんすべての signal を mask しておく必要がある。 子プロセスでは SIG_DFL に変えた後に mask を戻す。 もちろん親プロセスでも mask を戻す。 なお、glibc では NPTL で使われる SIGCANCEL (__SIGRTMIN) と SIGSETXID (__SIGRTMIN + 1) は mask できないようである。 これについては次に述べる。
- pthread_cleanup_push で登録した cancellation cleanup handler も呼び出されるのは困る。 glibc では cancel は SIGCANCEL で実装されているようだが、上記のように SIGCANCEL は mask できない。 ただ、sigcancel_handler, sighandler_setxid を調べると、SIGCANCEL, SIGSETXID を受け取ったときは、 呼び出し元の pid が他のプロセスなら単に return するので他のプロセスから問題を起こすことはできそうにない。 そして、vfork したプロセス自身から cancel をすることもない。 このため、cleanup handler が呼び出されることはない。 (だから少なくとも glibc では関係ないのだが) いちおう、親プロセスで pthread_setcancelstate で PTHREAD_CANCEL_DISABLE して cancel が無効であることを宣言することもできる。
- vfork 時に pthread_atfork() で設定された fork handler が呼び出される可能性がある。 vfork は fork と基本的には同じ仕様なので、fork handler を呼び出してもおかしくない。 ただ、NPTL では呼び出さないらしく問題ない。 でも、LinuxThreads では呼び出すらしい。(LinuxThreads なら vfork を使わないようにしたほうがいいかもしれない。)
他に、意図せざるコードが動く可能性はあるだろうか。RTLD とか? async-signal-safe な関数をスレッドライブラリが wrap しているかもしれないのも心配。
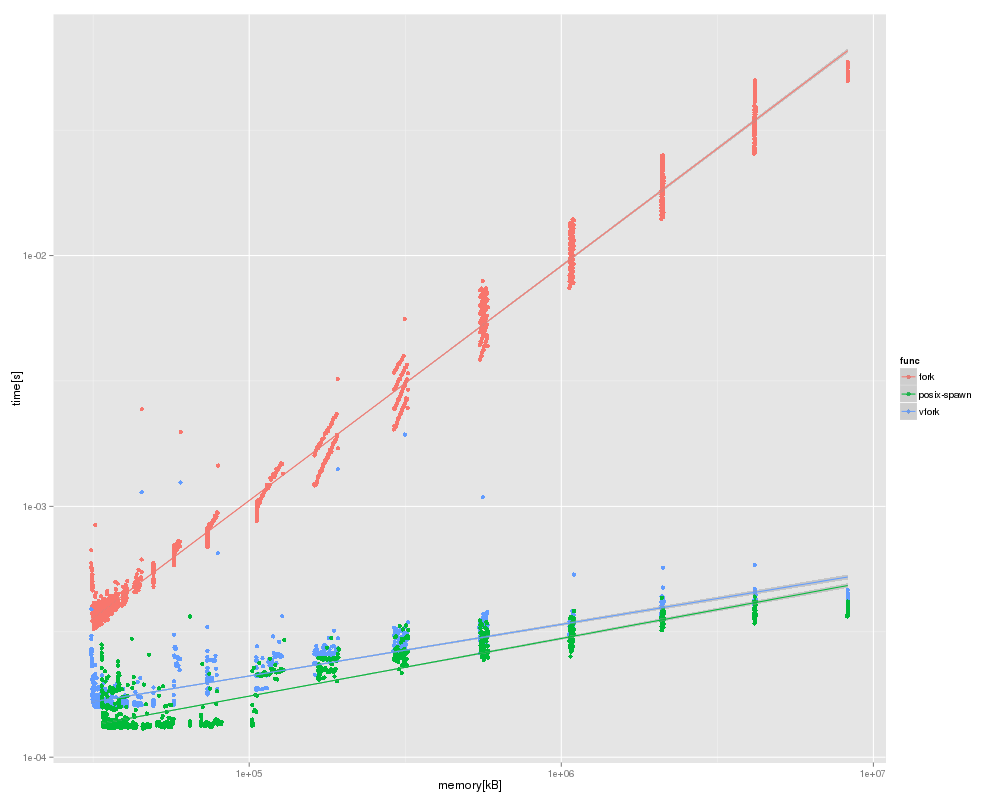
調べると、vfork を実際に使う話はいくつか見つかる。 libc で posix_spawn を実装する時に使う、というのが多い。
- vfork considered dangerous, musl libc のひとが、posix_spawn の実装に vfork を使ってすごく厄介だったという話。 signal, thread, setuid との関連。
- CERT Secure Coding: POS33-C. Do not use vfork() JPCERTによる和訳 vfork は使うな。
- Secure Programming for Linux and Unix HOWTO 8.6. Avoid Using vfork(2) vfork は使うな。
glibc の posix_spawn の実装 sysdeps/posix/spawni.c vfork が (POSIX_SPAWN_USEVFORK を指定しなくても) 有効になるのは以下の条件が成り立ったとき
(flags & (POSIX_SPAWN_SETSIGMASK | POSIX_SPAWN_SETSIGDEF | POSIX_SPAWN_SETSCHEDPARAM | POSIX_SPAWN_SETSCHEDULER | POSIX_SPAWN_SETPGROUP | POSIX_SPAWN_RESETIDS)) == 0 && file_actions == NULL- glibc bugzilla: Bug 378 - posix_spawn implementation, use vfork/execve rather than fork/execve for NPTL Linux. (2004-09-10) posix_spawn で vfork を使おうという最初の提案。 子プロセスで動く atfork handler が親プロセスを壊したらどうするのか、というのが懸念されている。 自己責任で、ということで POSIX_SPAWN_USEVFORK が追加された。
- glibc bugzilla: Bug 10354 - posix_spawn should use vfork() in more cases than presently (2009-06-30) vfork をもっと使ってほしいという要望に対し、すべての file operation は cancellation point だからそういうのを使う場合はダメ、と返されている。
- glibc bugzilla: Bug 14749 - Dangerous race condition with vfork in posix_spawn (2012-10-21) どっちかが setuid すると、メモリ共有でまずいことが起きるかも。
- glibc bugzilla: Bug 14750 - Race condition in posix_spawn vfork usage vs signal handlers (2012-10-21) signal handler でまずいことが起きるかも。
- NetBSD ドキュメンテーション: なぜ伝統的な vfork()を実装したのか NetBSD 1.3 で伝統的な vfork を実装した。いまでも fork より vfork が速い理由。
- NetBSD: posix_spawn syscall added 2011年から2012年ごろに NetBSD は posix_spawn をシステムコールとして実装した。
- FreeBSD の posix_spawn 常に vfork を使っていて、signal や setuid はとくに気にしていない?
- freebsd-hackers: system() using vfork() or posix_spawn() (2012-08-09) vforked child が sigaction を呼んだときに、親プロセスの他のスレッドも sigaction を呼んでいるとちゃんと同期しないといけないと指摘がある。 ユーザメモリに lock があって排他しているような関数は async-signal-safe ではないので呼んではいけないというのが基本だろうが、 signal まわりはいじりたいのも確かではある。 でも、SUSv4 では、sigaction, sigprocmask も含め、signal まわりの関数は async-signal-safe だから問題ないかも。
- freebsd-hackers: Change vfork() to posix_spawn()? (2012-09-14) FreeBSD では vfork した子プロセスが exec/exit するまでは stop signal を受け付けないとか、 POSIX_SPAWN_RESETIDS は euid/egid しか変えなくて、scheduling parameter を変更する権限には関係ないから問題ないぽいとか、いろいろな考察が書いてある。
- OpenBSD and vfork OpenBSD の vfork は exec/_exit するまで親を待たせる fork として実装されている。 メモリは共有されない。
- uClinux: We have no Fork uClinux には fork がなく、vfork がある。
- Solaris: Minimizing Memory Usage for Creating Application Subprocesses マルチスレッドな親プロセスから vfork したとき、子プロセスで dynamic linker が動くと、 そこで lock が必要になり、親プロセスですでに lock していると dead lock になる。 これは、親プロセスでは、vfork を呼ばなかった別スレッドも止まっていることを意味するように思える。
- 古い Autoconf のマニュアルの和訳の AC_FUNC_VFORK の項 AC_FUNC_VFORK の説明の中に「ただし、子プロセスでsignalを呼んでも 親プロセスのシグナルハンドラが変更されない場合には これはバグつきとはみなされません。」という記述がある。 これは、子プロセスで signal を呼んだときに、親プロセスのシグナルハンドラが変更される環境があることを示している気がする。 シグナルハンドラの設定がユーザメモリにある環境が存在する? むしろそうなってもらっては困るのだが。
- vfork and the signal race GNUnet で vfork が必要になった状況について。 vfork をつかうと、子プロセスが exec するまで親プロセスが動かないので、 その時間に親プロセスのシグナルハンドラが動くことがなく、それが都合がいい、という話。 fork でも避けることは可能だがエレガントでないという主張。
追記
- 2011 Ruby: posix-spawn 0.3.0 (gem) Ruby の posix-spawn gem は posix_spawn を使ってプロセスを起動する。
- 2013 fish: Release Notes for fish GitHub fish-shell/fish-shell#11 fish 2.0.0 で、可能なら posix_spawn を使うようになった
- 2015 Kazuho's Weblog: How to properly spawn an external command in C (or not use posix_spawn) glibc の posix_spawn は execve に失敗しても posix_spawn 自体は成功してしまうので、使えない。 コマンド起動は fork と FD_CLOEXEC な pipe を使って実装する。 (この glibc の posix_spawn の問題は glibc 2.24 で解決している)
- 2015 ruby: deadlock on Solaris 10 since r50900 現在の Solaris でも vfork を使うと dynamic linker で問題が発生する
- 2015 D: std.process: use vfork when possible D で vfork を使うという提案。vfork で作られた子プロセスでは execve と _exit 以外のシステムコールは呼べないからダメ、ということで reject されている。 clone() ならいいのではないか、とコメントされている。
- 2016 FreeBSD vfork.2 libthr では signal handler が部分的に user space で実装されているので親プロセスの状態を壊すという記述が足されている。
- 2016 glibc: posix: New Linux posix_spawn{p} implementation glibc の posix_spawn は vfork じゃなくて、clone システムコールを直接使うようになった。 これにより子プロセスのスタックは新しく確保されるようになり、親プロセスのスタックは共有されないのでトラブルが減る。
- 2016 perl5: vfork should be used for spawning external processes github issue perl で vfork を使うようにする提案
- 2017 golang: syscall: use CLONE_VFORK and CLONE_VM Go言語でも clone システムコール (に vfork 相当の親子プロセスでのメモリ共有をするフラグを指定したもの) を使うようになった。 プロセスを起動するときに、他の全ての goroutine が止まることによって、全体のスループットが落ちることが問題として述べられている。 対応するissue: syscall: use posix_spawn (or vfork) for ForkExec when possible #5838
- 2017 OCaml: spawn 0.9.0 (opam package) OCaml でプロセスを起動するための opam パッケージ。 起動するプロセスのカレントディレクトリを指定できる、 エラーの情報を適切に得られる、 可能なら vfork を使ってプロセスを起動する、 というのが主な狙い。
- 2018 ksh: Use fork()/exec() instead of posix_spawn() by default ksh は posix_spawnではなく fork/exec を使うように戻した。 posix_spawn だと terminal foreground process group を設定するのに race が発生してしまうのが理由。
- 2018 python: use os.posix_spawn in subprocess Python で posix_spawn を使うようにしようという話。 2019-10 にリリースされた Python 3.8 に導入された。
- 2018 Solaris: posix_spawn() as an actual system call Solaris 11.4 では posix_spawn は system call になる。(それ以前は vfork で実装されたライブラリ関数だった)
- 2018 GNOME/GLib: Use posix_spawn for optimized process launching glib では posix_spawn を使うようになった
- 2018 Rust: Command: Support posix_spawn() on FreeBSD/OSX/GNU Linux Rust は posix_spawn を使うようになった。glibc の場合、2.24 未満なら使わないようになっている。 posix_spawn_file_actions_addchdir_np が (Solaris および glibc 2.29 以降のように) 存在すれば 利用する。
- 2018 D: Use vfork on Linux when available D で vfork を使う提案。vfork した子プロセスでは _exit(2) か exec(3) family しか呼べないのでダメ
- 2018 D: Add bindings for POSIX's spawn.h D で posix_spawn への binding の追加が実装された
- 2019 glibc 2.29 glibc 2.29 では posix_spawn_file_actions_addchdir_np と posix_spawn_file_actions_addfchdir_np が追加された。
- 2019 python: Use vfork() in subprocess on Linux Python で vfork を使うようにしようという話。
- 2019 java: JDK 12 JDK 12 では、Linux 上で jdk.lang.Process.launchMechanism に POSIX_SPAWN を指定可能になった。 デフォルトは VFORK のままで変更なし。 (なお、他のプラットフォームではしばらく前から POSIX_SPAWN がデフォルトな模様)
- 2019 .NET: Use vfork() improve performance when starting processes. .NET でも vfork を使うようになった。パッチを見ると、OS X では使わないようになっている。
- 2020 GNU make: GNU make 4.3 released! きっかけとなった質問 パッチと議論 GNU make 4.3 は posix_spawn を使うようになった。 提案した人の理由は、fork と vfork はないけれど、posix_spawn はある、という環境で使いたい、というもの。 その環境は Threos と思われる。
- 2020 Let's talk about posix_spawn, and when to use it. posix_spawn の利点は速いこと。欠点は flexibility および error の扱い。 posix_spawn では tcsetpgrp を扱えないことを指摘している。 また、posix_spawn が子プロセスの中で行うさまざまな操作のどれが失敗したのか情報が得られない。