とりあえず無駄に利用しているメモリは削るか、ということで、今までは key を文字列にしていたのを、整数にしてみた。
% ./ruby -rPAPI -e '
events = %w[PAPI_L1_DCM PAPI_L2_DCM PAPI_L3_TCM]
evset = PAPI::EventSet.new
evset.add_named(events)
puts "n,l1,l2,l3"
rep1 = 100
rep2 = 100
nn = 1.0
ns = []
while nn < 2e4
ns << nn.to_i
nn = nn*1.001
end
ns = ns * rep1
ns.shuffle!
GC.disable
ns.each {|n|
h = {}
h[h.size] = true while h.size < n
l1sum = l2sum = l3sum = 0
GC.start
rep2.times {|i|
k = rand(n)
evset.start; evset.stop
evset.start
h[k]
evrec = evset.stop
l1sum += evrec[0]
l2sum += evrec[1]
l3sum += evrec[2]
}
l1mean = l1sum.to_f / rep2
l2mean = l2sum.to_f / rep2
l3mean = l3sum.to_f / rep2
puts "#{n},#{l1mean},#{l2mean},#{l3mean}"
}' > hash-lookup-cache-intkey.csv
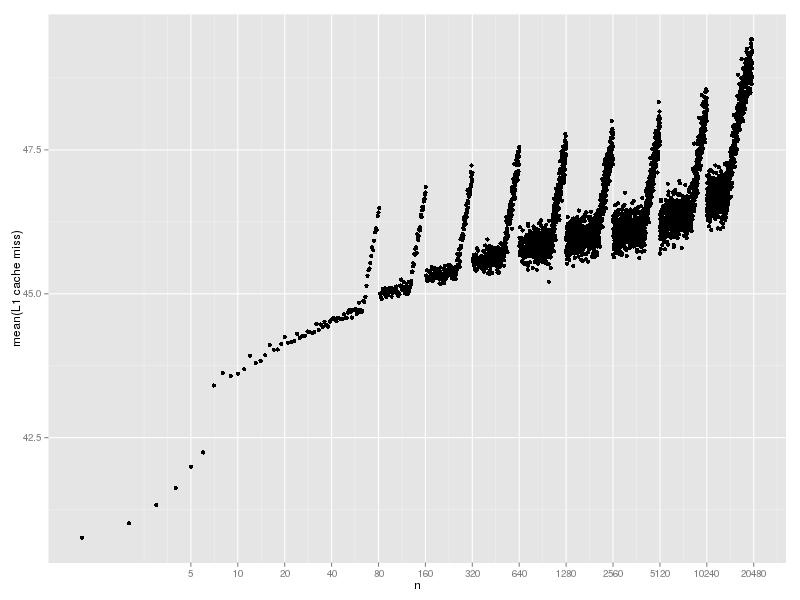
L1 cache miss は以下のようになった。うぅむ、なんですかねこの折れ線は。
hash-lookup-cache-intkey-l1.R:
library(ggplot2)
library(plyr)
d <- read.csv("2016-11/hash-lookup-cache-intkey.csv.xz")
dl1 <- ddply(d, .(n), colwise(mean, .(l1)))
p <- ggplot(dl1, aes(n, l1)) +
geom_point() +
scale_x_log10(breaks = 5*2**(0:24)) +
ylab("mean(L1 cache miss)")
print(p)
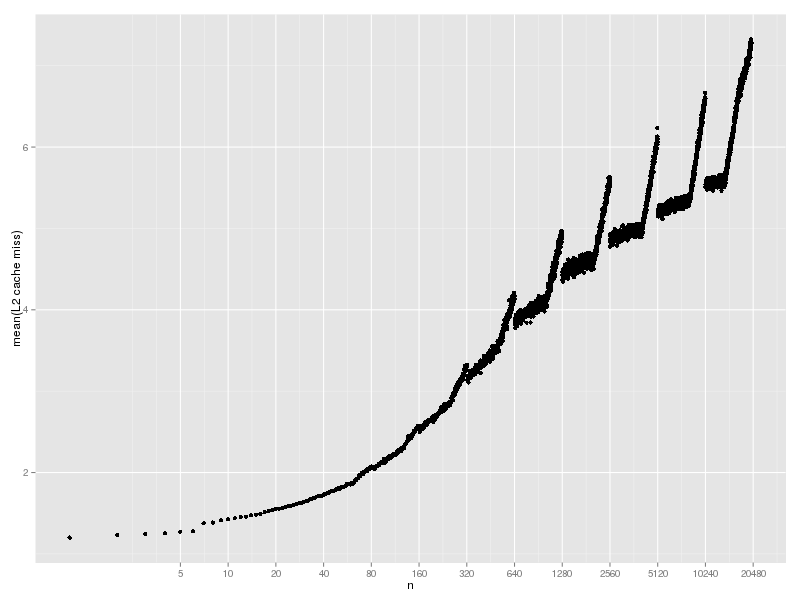
L2 cache miss は以下のようになった。これも折れ線になっている。
hash-lookup-cache-intkey-l2.R:
library(ggplot2)
library(plyr)
d <- read.csv("2016-11/hash-lookup-cache-intkey.csv.xz")
dl2 <- ddply(d, .(n), colwise(mean, .(l2)))
p <- ggplot(dl2, aes(n, l2)) +
geom_point() +
scale_x_log10(breaks = 5*2**(0:24)) +
ylab("mean(L2 cache miss)")
print(p)
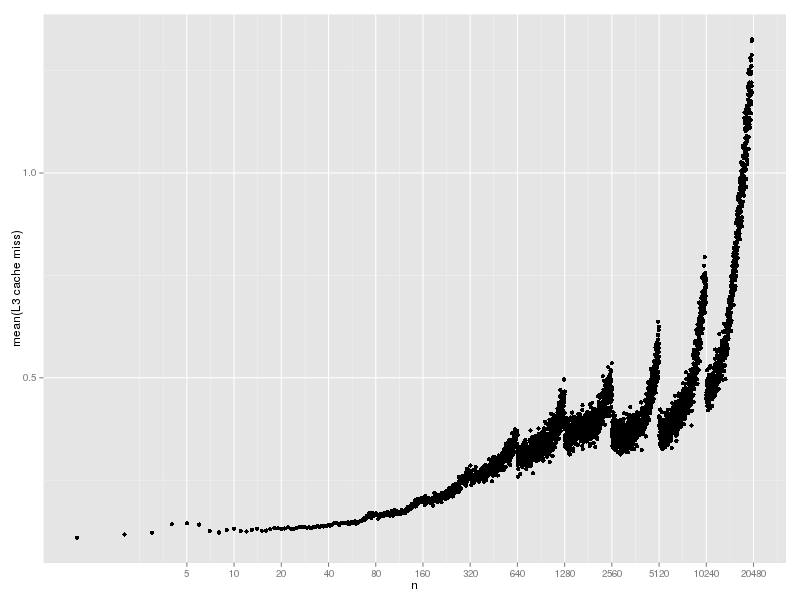
L3 cache miss は以下のようになった。これは曲線のままだな。
hash-lookup-cache-intkey-l3.R:
library(ggplot2)
library(plyr)
d <- read.csv("2016-11/hash-lookup-cache-intkey.csv.xz")
dl3 <- ddply(d, .(n), colwise(mean, .(l3)))
p <- ggplot(dl3, aes(n, l3)) +
geom_point() +
scale_x_log10(breaks = 5*2**(0:24)) +
ylab("mean(L3 cache miss)")
print(p)
L1/L2 cache miss の折れ線はなんだろうな。周期から考えて、rehash に関係しているとは思うのだが。(最初の rehash の n=80 を含め、rehash の直前で miss が急激に増えているのはどういう理屈なのだろうか。
なお、key を変えても、miss が目立ち始めるサイズはたいして変わらず、理屈と合わないという点に関しては変化は見られなかった。