(x86 で) -fomit-frame-pointer は有効なのか?
検索したら、「x86 系の CPU では,かえって逆効果となってしまう場合もある」 という話もあるようだ。
ruby の trunk は今デフォルトで -O3 -fomit-frame-pointer なので、ちょっと試してみよう。
% uname -a
Linux nute 2.6.26-1-486 #1 Fri Mar 13 17:25:45 UTC 2009 i686 GNU/Linux
-O3 -fomit-frame-pointer (デフォルト):
% valgrind --tool=cachegrind ./miniruby -e ''
==26841== Cachegrind, a cache and branch-prediction profiler.
==26841== Copyright (C) 2002-2007, and GNU GPL'd, by Nicholas Nethercote et al.
==26841== Using LibVEX rev 1854, a library for dynamic binary translation.
==26841== Copyright (C) 2004-2007, and GNU GPL'd, by OpenWorks LLP.
==26841== Using valgrind-3.3.1-Debian, a dynamic binary instrumentation framework.
==26841== Copyright (C) 2000-2007, and GNU GPL'd, by Julian Seward et al.
==26841== For more details, rerun with: -v
==26841==
==26841==
==26841== I refs: 9,370,973
==26841== I1 misses: 16,396
==26841== L2i misses: 5,440
==26841== I1 miss rate: 0.17%
==26841== L2i miss rate: 0.05%
==26841==
==26841== D refs: 4,479,783 (2,905,951 rd + 1,573,832 wr)
==26841== D1 misses: 32,644 ( 21,069 rd + 11,575 wr)
==26841== L2d misses: 13,979 ( 3,363 rd + 10,616 wr)
==26841== D1 miss rate: 0.7% ( 0.7% + 0.7% )
==26841== L2d miss rate: 0.3% ( 0.1% + 0.6% )
==26841==
==26841== L2 refs: 49,040 ( 37,465 rd + 11,575 wr)
==26841== L2 misses: 19,419 ( 8,803 rd + 10,616 wr)
==26841== L2 miss rate: 0.1% ( 0.0% + 0.6% )
-fomit-frame-pointer を外して -O3 だけ:
% valgrind --tool=cachegrind ./miniruby -e ''
==26847== Cachegrind, a cache and branch-prediction profiler.
==26847== Copyright (C) 2002-2007, and GNU GPL'd, by Nicholas Nethercote et al.
==26847== Using LibVEX rev 1854, a library for dynamic binary translation.
==26847== Copyright (C) 2004-2007, and GNU GPL'd, by OpenWorks LLP.
==26847== Using valgrind-3.3.1-Debian, a dynamic binary instrumentation framework.
==26847== Copyright (C) 2000-2007, and GNU GPL'd, by Julian Seward et al.
==26847== For more details, rerun with: -v
==26847==
==26847==
==26847== I refs: 9,133,682
==26847== I1 misses: 11,399
==26847== L2i misses: 5,189
==26847== I1 miss rate: 0.12%
==26847== L2i miss rate: 0.05%
==26847==
==26847== D refs: 4,445,172 (2,854,183 rd + 1,590,989 wr)
==26847== D1 misses: 30,750 ( 19,734 rd + 11,016 wr)
==26847== L2d misses: 13,374 ( 3,267 rd + 10,107 wr)
==26847== D1 miss rate: 0.6% ( 0.6% + 0.6% )
==26847== L2d miss rate: 0.3% ( 0.1% + 0.6% )
==26847==
==26847== L2 refs: 42,149 ( 31,133 rd + 11,016 wr)
==26847== L2 misses: 18,563 ( 8,456 rd + 10,107 wr)
==26847== L2 miss rate: 0.1% ( 0.0% + 0.6% )
いきなり逆効果である。
minieruby -e '' だけでも、命令実行数 (I refs) が -fomit-frame-pointer なしの方が小さい。
しかし、
repeat 100 ./miniruby -e '10000000.times {}; p Process.times.utime'
として実行時間を測ってみると、-fomit-frame-pointer をつけた方がいくらか速いようだ。
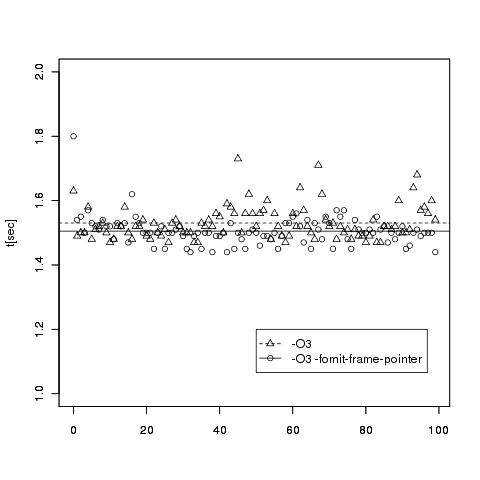
omit-fp.R:
n <- seq(0, 99)
with_omit_frame_pointer = c(
1.8, 1.54, 1.55, 1.5, 1.57, 1.53, 1.52, 1.51, 1.54, 1.52,
1.52, 1.48, 1.53, 1.52, 1.53, 1.47, 1.62, 1.55, 1.53, 1.5,
1.5, 1.5, 1.45, 1.5, 1.52, 1.45, 1.5, 1.5, 1.51, 1.52,
1.49, 1.45, 1.44, 1.49, 1.5, 1.45, 1.5, 1.5, 1.44, 1.49,
1.49, 1.5, 1.44, 1.53, 1.45, 1.5, 1.48, 1.45, 1.5, 1.51,
1.5, 1.46, 1.49, 1.49, 1.48, 1.5, 1.45, 1.49, 1.53, 1.53,
1.55, 1.56, 1.52, 1.47, 1.54, 1.45, 1.53, 1.51, 1.48, 1.55,
1.53, 1.45, 1.57, 1.55, 1.57, 1.48, 1.45, 1.54, 1.51, 1.5,
1.5, 1.51, 1.5, 1.55, 1.51, 1.52, 1.47, 1.5, 1.48, 1.5,
1.52, 1.45, 1.46, 1.5, 1.51, 1.49, 1.5, 1.5, 1.5, 1.44)
without_omit_frame_pointer = c(
1.63, 1.49, 1.5, 1.5, 1.58, 1.48, 1.51, 1.52, 1.53, 1.5,
1.47, 1.48, 1.52, 1.52, 1.58, 1.5, 1.48, 1.52, 1.52, 1.54,
1.49, 1.48, 1.53, 1.5, 1.49, 1.51, 1.47, 1.53, 1.54, 1.52,
1.5, 1.5, 1.5, 1.47, 1.47, 1.53, 1.52, 1.54, 1.52, 1.56,
1.55, 1.5, 1.59, 1.58, 1.56, 1.73, 1.5, 1.56, 1.62, 1.56,
1.52, 1.56, 1.57, 1.6, 1.48, 1.56, 1.52, 1.49, 1.47, 1.49,
1.56, 1.52, 1.64, 1.57, 1.52, 1.5, 1.48, 1.71, 1.62, 1.54,
1.52, 1.53, 1.48, 1.52, 1.5, 1.51, 1.48, 1.51, 1.49, 1.49,
1.47, 1.49, 1.54, 1.47, 1.47, 1.52, 1.52, 1.51, 1.52, 1.6,
1.5, 1.5, 1.51, 1.64, 1.68, 1.57, 1.58, 1.56, 1.6, 1.54)
plot(n,with_omit_frame_pointer, xlab="", ylab="t[sec]", ylim=c(1,2))
abline(mean(with_omit_frame_pointer), 0)
par(new=T)
plot(n,without_omit_frame_pointer, xlab="", ylab="", ylim=c(1,2), pch=2)
abline(mean(without_omit_frame_pointer), 0, lty=2)
legend(50, 1.2, c("-O3", "-O3 -fomit-frame-pointer"), pch=c(2,1), lty=c(2,1))